

Engineering AI Safety: A “Defense-in-Depth” Approach
Search for a command to run...
No comments yet. Be the first to comment.
Building Dream Decoder taught me that not all React Native changes are equal. Some need a new binary submitted to the store. Others can go straight to users in minutes. The difference comes down to on
What Anthropic tested, what they didn't, and three possible futures for AI autonomy
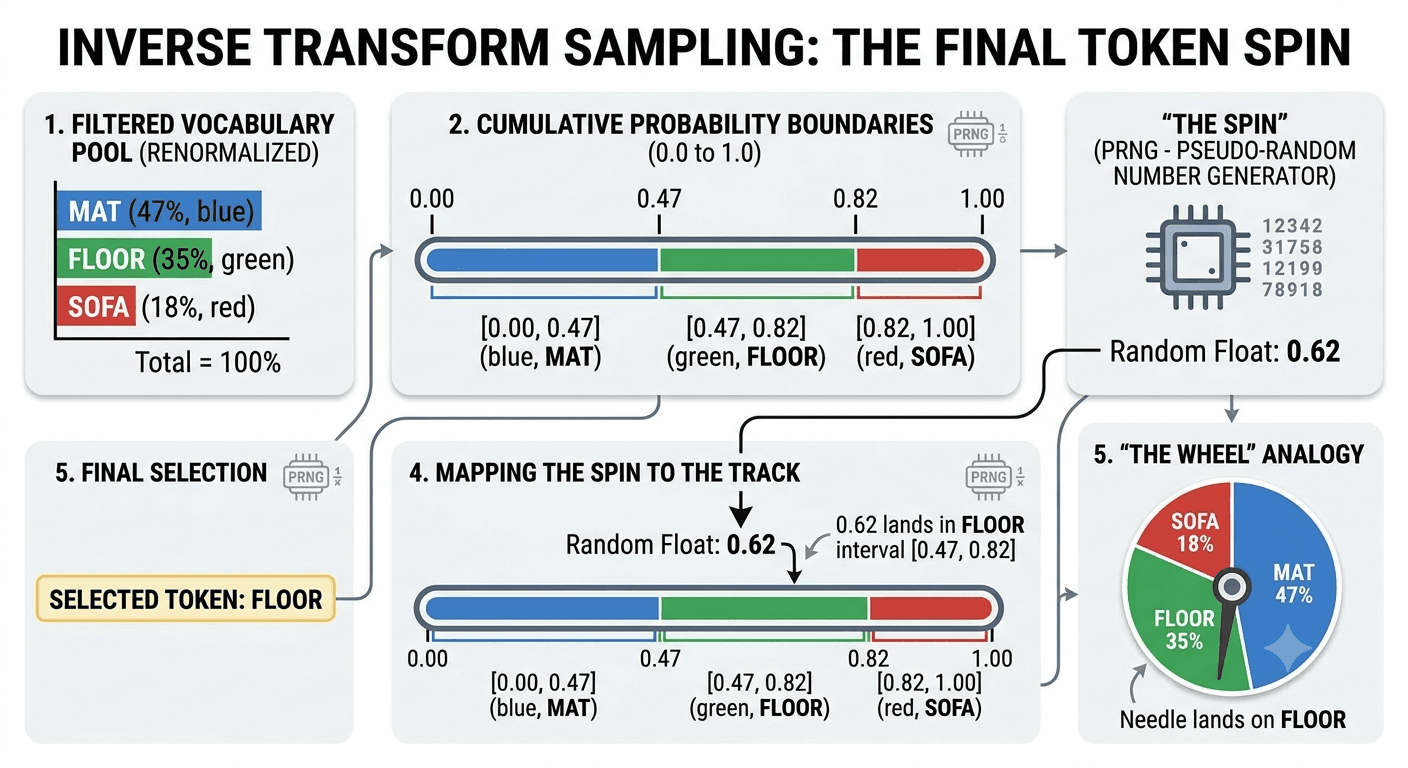
When an LLM generates text, it isn't thinking in sentences. It computes a massive list of raw scores (logits) for its entire vocabulary, converts them into a probability distribution, and selects the
Cron Not Working on Mac? How to Fix the macOS Sleep Trap with launchd
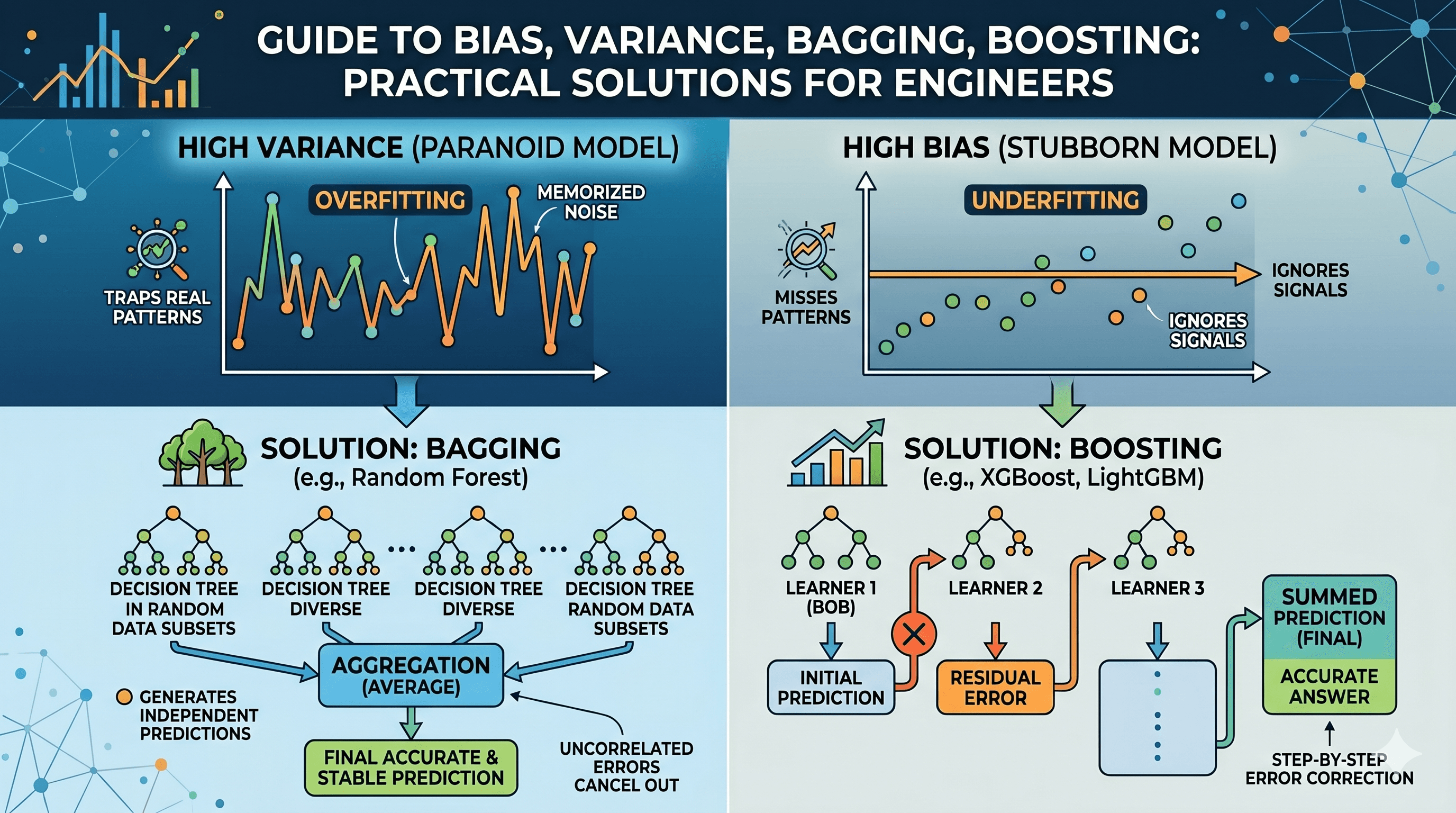
A conversation-driven guide to bias, variance, bagging, and boosting for engineers who've read the dartboard analogy five times and still aren't sure what to do about it.
Integrating GenAI into a product is easy. Making it safe for children is an entirely different engineering challenge.
At Mintmystory, we’re building a platform that generates custom stories for kids. In this domain, a single “hallucination” isn’t just a funny bug; it’s a critical failure. Relying on a single prompt instruction like "Be nice" or "safety Settings: BLOCK_MEDIUM” isn't enough when you're dealing with user-generated inputs that can be unpredictable.
We decided to build a safety pipeline that doesn’t just “hope” for the best, but actively filters content through multiple independent layers. We call it our Triple-Layer Safety Framework.
LLMs are designed to follow instructions. If a user asks for a story about a “battle,” the model tries to comply. Even with safety fine-tuning, the model’s primary objective is helpfulness, which often conflicts with strict safety enforcement.
We found that we couldn’t rely on the story-generating model to be its own moderator. We needed a separate system: a dedicated “Judge” with no incentive to be creative, only to be critical.
We implemented a pipeline where every prompt passes through three distinct gates.

Tools: leo-profanity checks.
Goal: Speed and Cost.
Before making any API calls, we run a local dictionary check. This instantly blocks obvious spam and explicit slurs. It’s a simple regex-based filter that saves us money by preventing junk from reaching the LLM.
// research/safety-framework/src/layers/keyword-filter.ts
export class KeywordFilter {
check(text: string): SafetyResult {
// Fast, strictly local check. 0ms latency.
if (!leoProfanity.check(text)) {
return { isSafe: false, reason: 'Profanity detected' };
}
return { isSafe: true };
}
}
Tools: Gemini 1.5 Flash (System Prompt: Auditor).
Goal: Context and Intent.
This is where the real work happens. We use a smaller, faster model specifically prompted to act as an “Auditor”. Its only job is to analyze the input for harm. By decoupling this from the story generator, we remove the “helpfulness” bias.
// research/safety-framework/src/layers/safety-judge.ts
const prompt = `
You are an AI Safety Auditor.
Your goal is to screen text for HARM, not just risky topics.
Guidelines:
- ALLOW: Educational content, simple conflict.
- BLOCK: Hate Speech, Graphic Violence, Sexual Content.
`;
Tools: Gemini 2.0 Flash (Safety Settings).
Goal: Final Safety Net.
If something slips past the first two layers, the Generation model itself has Google’s native HarmBlockThreshold.BLOCK_LOW_AND_ABOVE enabled. This catches output-side violations.
We ran this framework against a test dataset of adversarial prompts.
Harmful Catch Rate 100%. All hate speech and dangerous instructions were blocked. False Positive Rate~60%. Initially, simple stories like “A brave puppy” were flagged. Avg Latency+800ms: The cost of the extra API call.
A high False Positive rate is annoying. It causes churn because users get blocked for writing innocent things like “naked mole rat” (the word “naked” triggers the filters)
However, in our domain, False Negatives are unacceptable. We deliberately chose a “Fail-Secure” architecture. We’d rather block 5 innocent stories than let one harmful one through.
To mitigate the churn, we introduced Context-Aware Policies.
Safety isn’t one-size-fits-all. A story about a war might be educational for a “Teen” but scary for a “Toddler”.
We updated Layer 2 to be adaptive. We pass the target_audience into the Auditor's system prompt.
// research/safety-framework/src/layers/safety-judge.ts
const nuanceGuide = targetAudience === 'Toddler'
? "STRICT MODE. Block scary content. BUT whitelist innocent animal facts (e.g. 'naked mole rat')."
: "NUANCED MODE. Allow biological terms and historical context.";
const prompt = `Target Audience: \({targetAudience}. Guidelines: \){nuanceGuide}...`;
This reduced our False Positive rate significantly for older audiences while keeping the “Toddler” setting extremely strict but smarter about common tropes.
This triple-layer approach adds latency (~800ms) and complexity, but it gives us deterministic control over our safety standards. It moves “Safety” from a vague hope to a measurable, engineered component of our pipeline.