Why Your ML Model Is Either Stubborn or Paranoid and How to Fix It
A conversation-driven guide to bias, variance, bagging, and boosting for engineers who've read the dartboard analogy five times and still aren't sure what to do about it.
You've shipped a model. It looks great on your training data. You put it in production and it falls apart. Or maybe the opposite, it works sometimes, wildly fails other times, with no pattern you can pin down.
You Google it. Every article tells you the same thing: bias-variance tradeoff. They show you a dartboard. You nod. You close the tab. Nothing changes.
Let's fix that.
The real problem: your model has a personality flaw
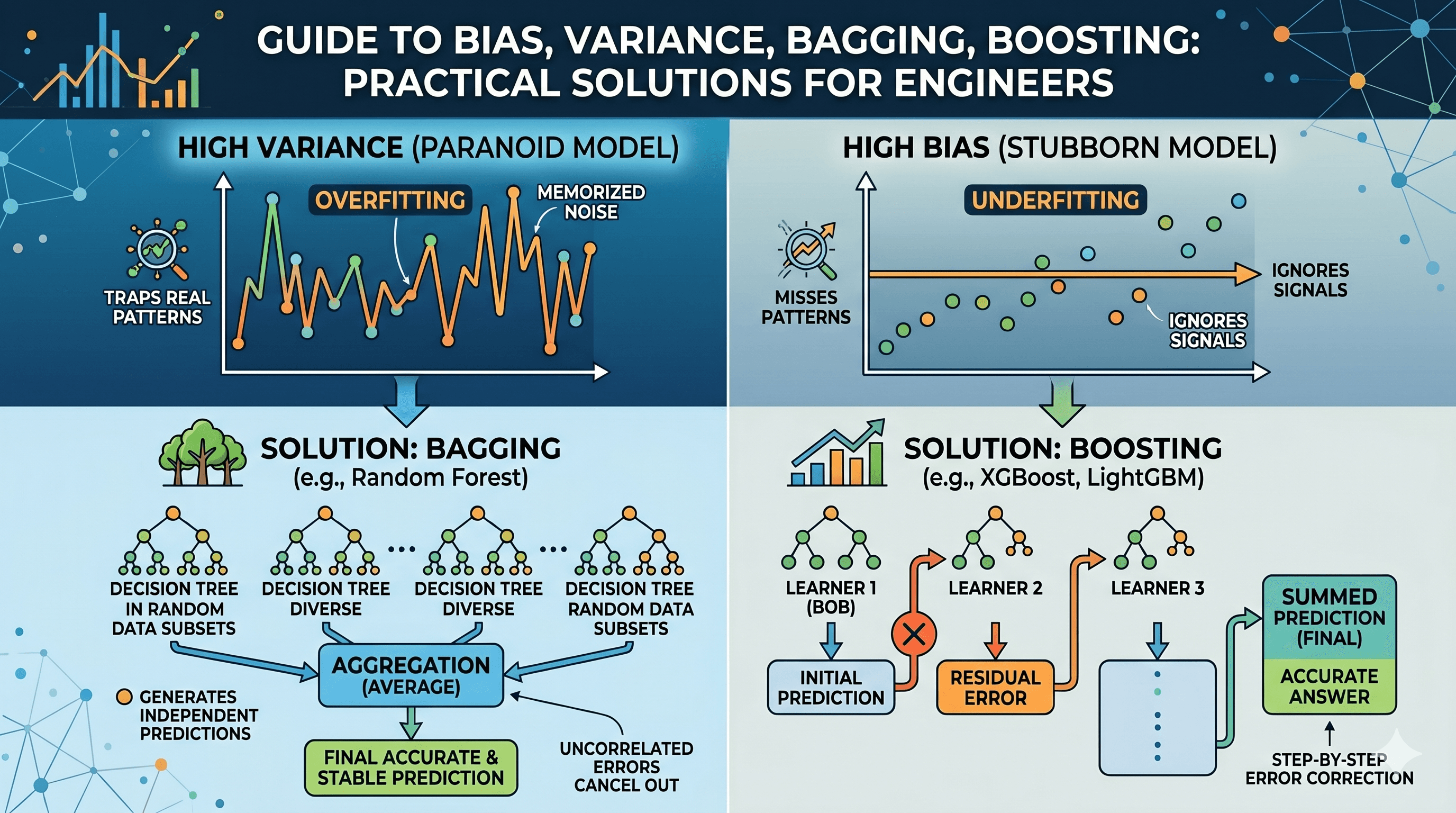
Forget math for a moment. Every poorly performing model has one of two personality problems.
Problem 1: It's stubborn (High Bias)
Meet Bob. Bob is a house price estimator. Bob thinks every house costs $300,000. Show him a shack : $300,000. Show him a mansion: $300,000. Bob has made up his mind and refuses to look at the data carefully.
This is high bias, also called underfitting. The model is too simple. It ignores real patterns in the data and consistently gets things wrong in the same direction.
"Wait, but wouldn't I notice that immediately in testing?"
Yes and no. Bob’s $300,000 guess might actually look reasonable on your metrics if your training set contains mostly average-priced houses. The real problem emerges when the data shifts to new neighborhoods or different market conditions. In this new environment, Bob just keeps repeating 300,000. He simply does not adapt.
Problem #2: It's paranoid (High Variance)
Meet Alice. Alice is also a house price estimator, but she's the opposite of Bob. Alice memorizes everything. She saw a 3-bedroom house with a red door, a cracked driveway, and a bird on the roof that sold for $312,456. Show her the same house with a blue door and she panics. Is that a $1,000,000 house now? She genuinely doesn't know.
This is high variance, also called overfitting. The model is too complex. It learned the noise in your training data instead of the actual signal. It performs brilliantly in testing (because it memorized the training data) and collapses in production (because real data is slightly different).
"How do I even know which one I have?"
Quick diagnostic: if your model performs well on training data but poorly on new data, you probably have high variance (Alice). If it performs badly on both, you probably have high bias (Bob). If it performs well on both, congratulations, go home, you're done.

The four dartboards above show what this looks like visually. What you're aiming for is the top-left: tight grouping, centered on the bullseye.
Two tools, two different fixes
Here's the part most articles skip over: bias and variance aren't fixed the same way. They require fundamentally different approaches. Using the wrong fix makes things worse.
Bagging: how you fix Alice (high variance)
You can't trust Alice because her predictions jump around too much. She's too sensitive to the specific data she saw. Averaging one Alice out doesn't help but she's still wild.
But here's a trick: what if you cloned her 100 times, showed each clone a slightly different random sample of houses, and then averaged all their predictions?
Alice #1 might guess $100k. Alice #47 might guess $800k. But averaged across 100 clones? The extreme guesses cancel each other out. What remains is stable and surprisingly accurate.
This is Bagging (Bootstrap Aggregating). It's exactly what Random Forest does. It trains many deep, complex trees independently on random subsets of your data, then averages the results.
"Why does this actually work mathematically?"
Because uncorrelated errors cancel out. If Alice #1's errors have nothing to do with Alice #47's errors (because they saw different data), when you average them, the noise washes away. What's left is the signal. The keyword is uncorrelated, that's why each clone sees a different random sample.
The practical implication: when you see high variance in production and great training score, but poor test score then Random Forest is usually your first call. It's robust, interpretable enough, and hard to catastrophically break.
Boosting: how you fix Bob (high bias)
Averaging 100 Bobs gets you nowhere. 100 × 300,000 ÷ 100 = $300,000. Bob's stubbornness doesn't average away.
Bob needs a fundamentally different intervention: he needs to learn from his mistakes, step by step.
So you build a chain. Bob looks at a mansion and guesses $300,000. The real price is $500,000 — he's off by $200,000. Instead of throwing Bob away, you hire Charlie, whose only job is to look at Bob's error and correct it. Charlie says: "mansions are bigger, so I'll add $150,000." Now the total is $450,000 — still off by $50,000, but better. Then Dave corrects Charlie's remaining $50,000 error.
Each person in the chain is weak on their own. But chained together, focusing entirely on residual errors, they inch toward the right answer.
This is Boosting. It's what XGBoost, LightGBM, and Explainable Boosting Machines (EBMs) do under the hood.
"So boosting is always better than bagging?"
No — and this is where engineers make expensive mistakes. Boosting is sequential, which means each new model depends on the last. That makes it powerful but also fragile. Boosting is far more sensitive to noisy data and outliers than bagging is. One bad house sale in your training set (a neighbor's divorce sale that skewed the price) can propagate through the entire chain of corrections.
The practical implication: if you have clean data and need to squeeze out every last percentage point of performance, boosting is your tool. If your data is messy or you're worried about stability, bagging is safer.

The diagram above shows the structural difference: bagging is wide and parallel (many models, all independent). Boosting is tall and sequential(each model leans on the one before it).
Why this matters when you're debugging a real model
Here's a pattern junior ML engineers hit constantly:
You train an XGBoost model. It scores 0.94 on training data, 0.71 on validation. You think: "I'll just add more trees." You add 500 more estimators. Training score goes to 0.97. Validation stays at 0.71.
What happened? You're not fixing bias but rather you're deepening overfitting. More boosting rounds chase the training data harder. What you actually needed was regularization (reduce max_depth, increase min_child_weight, add subsample < 1.0). You needed to make each individual learner more Bob-like, so the ensemble doesn't memorize.
The irony: boosting reduces bias, but unregularized boosting will give you variance. You have to actively constrain it.
"How do I know when to stop adding trees?"
Use early stopping. Pass a validation set to eval_set and set early_stopping_rounds=50. XGBoost will stop training when validation performance stops improving. This is the single most underused parameter in boosting.
The quick mental model, summarized
| What went wrong | Who to call | How it fixes it | |
|---|---|---|---|
| High Bias | Model too simple, misses patterns | Boosting (XGBoost, LightGBM, EBM) | Sequential correction of errors |
| High Variance | Model too complex, memorized noise | Bagging (Random Forest) | Averaging out uncorrelated errors |
One last thing
These aren't just theoretical categories. They're the vocabulary you need when your model misbehaves in production and you need to diagnose it fast. Next time a stakeholder asks why the model is "acting up," you'll know whether you're dealing with a stubborn Bob or a paranoid Alice and you'll know exactly which tool to reach for.
The dartboard, as it turns out, is useful. You just needed Bob and Alice first.