How Temperature, Top‑K, and Top‑P Control LLM Output — A Practical Guide
When an LLM generates text, it isn't thinking in sentences. It computes a massive list of raw scores (logits) for its entire vocabulary, converts them into a probability distribution, and selects the next token.
How it makes that selection depends entirely on three parameters: Temperature, Top-K, and Top-P. If you configure these poorly, the model either loops infinitely into a repetitive wall of text or degenerates into pure gibberish.
The Base Layer: The Unscaled Logit Distribution
Before any sampling parameters or truncation filters are applied, the model's final linear layer (the LM head) outputs a vector of raw, unnormalized log-odds called logits.
To analyze a baseline, passing these raw logits through a standard Softmax function at a default Temperature (T = 1.0) converts the arbitrary scores into a normalized probability distribution where all values sum to 1.0. For the prompt, "The cat sat on the...", this default baseline distribution might yield:
mat: 0.40
floor: 0.30
sofa: 0.15
...and so on.
When you adjust Temperature to something other than 1.0, you are not modifying these probabilities directly. You are intercepting the pipeline before this Softmax step and dividing the underlying raw logits by the temperature factor:
$$z'_i = \frac{z_i}{T}$$
If you configure the interface for Greedy Search (conceptually denoted as T = 0), production inference engines bypass the Softmax equation entirely to avoid a division-by-zero error. Instead, they execute an explicit short-circuit path that applies an argmax() operation directly to the logit array, deterministically returning the token with the highest raw score every single time.
For non-greedy generation, we avoid picking the absolute top token by using Weighted Random Sampling. However, executing a random draw across the entire vocabulary wheel immediately after temperature scaling would risk selecting incoherent long-tail tokens (like "blue" or "run"). To prevent this, the inference engine routes the scaled logits through truncation filters to isolate a contextually safe nucleus of vocabulary before the final random number selection occurs.
Temperature (T)
So we have already touched upon Temperature on aforementioned paragraph but what is Temperature?
Temperature is an explicit mathematical scaling factor applied to the raw logits (z) before they pass through the Softmax function to become probabilities:
$$q_i = \frac{\exp(\frac{z_i}{T})}{\sum_{j} \exp(\frac{z_j}{T})}$$
It dictates how heavily the model favors high-confidence choices versus long-tail anomalies.
Mathematical Impact of Temperature on Distributions
Let z be the raw logit vector outputted by the model over a vocabulary of size V, where z(i) corresponds to token i.
Temperature Scaling
Temperature T scales the logits before the exponential calculation:
$$z'_i = \frac{z_i}{T}$$
Low Temperature (T < 1): Sharpening. The differences between logits are amplified. High-probability tokens explode toward 1.0, and lower ones drop to near 0. At T=0.2, "mat" might swallow 90% of the entire distribution. The gap between the largest logit and all others approaches infinity. Softmax turns into an indicator function (argmax), collapsing the distribution into a single peak (greedy decoding).
High Temperature (T > 1): Flattening. The differences shrink. The distribution becomes more uniform. The peak drops, and the long-tail tokens creep upward. At T=1.5, "mat" might drop to 0.22, while "blue" climbs to 0.08. The variance diminishes, flattening the distribution towards uniform randomness.
Top-K vs. Top-P: The Truncation Filter
Once temperature alters the shape of the landscape, the model needs to truncate the vocabulary to prevent completely incoherent selections. This is where Top-K and Top-P diverge—and why one is replacing the other.
Top-K (Fixed Count)
Top-K ranks the entire vocabulary by probability and discards everything outside the top K tokens. If K=3, the model strictly looks at {mat, floor, sofa} and ignores the rest.
The Flaw of Top-K: It is completely blind to confidence context. If the model is highly certain (e.g., predicting the next token in an explicit programming function name), the top 1 or 2 tokens might hold 99% of the probability. A K value of 50 forces the model to include 48 junk tokens in the selection pool anyway. Conversely, if the model is highly uncertain (e.g., an open-ended creative prompt), 100 different tokens might all be completely valid, but a strict K=10 filter will aggressively kill off 90 viable paths.
Top-P (Dynamic Nucleus)
Top-P addresses this by sampling from the smallest set of tokens whose cumulative probability meets a threshold P (e.g., P=0.85).
mat (0.40) -> Cumulative: 0.40
floor (0.30) -> Cumulative: 0.70
sofa (15) -> Cumulative: 0.85 -> Cutoff Met.
The pool dynamically adjusts. If the model is confident and the top token has a probability of 0.90, a P=0.85 filter narrows the selection pool to just that single token. If the model is confused and the top fifty tokens each have a 0.01 probability, the pool expands to include all fifty.
Because of this adaptability, Top-K has largely fallen out of favor in modern LLM architectures (like Llama or Mistral variants), which frequently rely exclusively on Top-P or newer variants like Min-P to handle truncation.
Production Note: In modern inference stacks, Top-P is treated as the primary control knob. Standard industry best practice is to adjust either Temperature or Top-P, but rarely both aggressively at the same time, as they can compound and flatten out the token selection pool chaotically.
Newer and Advanced Sampling Methods
As models have scaled, traditional Top-K and Top-P truncation techniques have revealed limitations. Modern production environments utilize more nuanced logit processors to balance diversity and coherence.
Min-P (Relative Threshold)
Min-P sets a minimum percentage requirement for tokens relative to the probability of the most likely token. For example, if the top token has a probability of 0.80 and Min-P = 0.1, the minimum cutoff threshold becomes 0.08 (0.80 * 0.1). Any token below 0.08 is discarded.
- Why it excels: Unlike Top-P, which can still let in low-probability "junk" tokens if it needs to fill out its cumulative percentage budget, Min-P strictly scales based on confidence. If the model is highly confident in one answer, the threshold scales up and locks out the rest. If the model is uncertain, the threshold scales down to allow safe exploration. It is highly robust at elevated temperatures (T > 1.0) where Top-P often breaks down.
Typical Sampling
Typical sampling shifts the focus away from raw probabilities entirely. It filters tokens based on how close their information content (entropy) is to the expected information content of human language at that step. It prioritizes tokens that sound "natural" or "typical" in context, preventing the model from picking jarring, out-of-character phrases even when executing creative tasks.
Penalties: Repetition, Frequency, and Presence
To prevent models from getting stuck in loops or repeating the same terms, inference engines adjust logits dynamically based on generation history:
Repetition Penalty: Multiplies the logits of tokens that have already appeared by a discounting factor (e.g., dividing by 1.2), making them less likely to reappear.
Presence Penalty: Applies a flat mathematical deduction to a token's logit if it has appeared at least once in the generated output, encouraging the model to introduce completely new topics or words.
Frequency Penalty: Applies a scaling deduction to a token's logit proportional to how many times it has already appeared, punishing overused words increasingly over time.
The Final Pick: Fair Randomness vs. Learned Bias
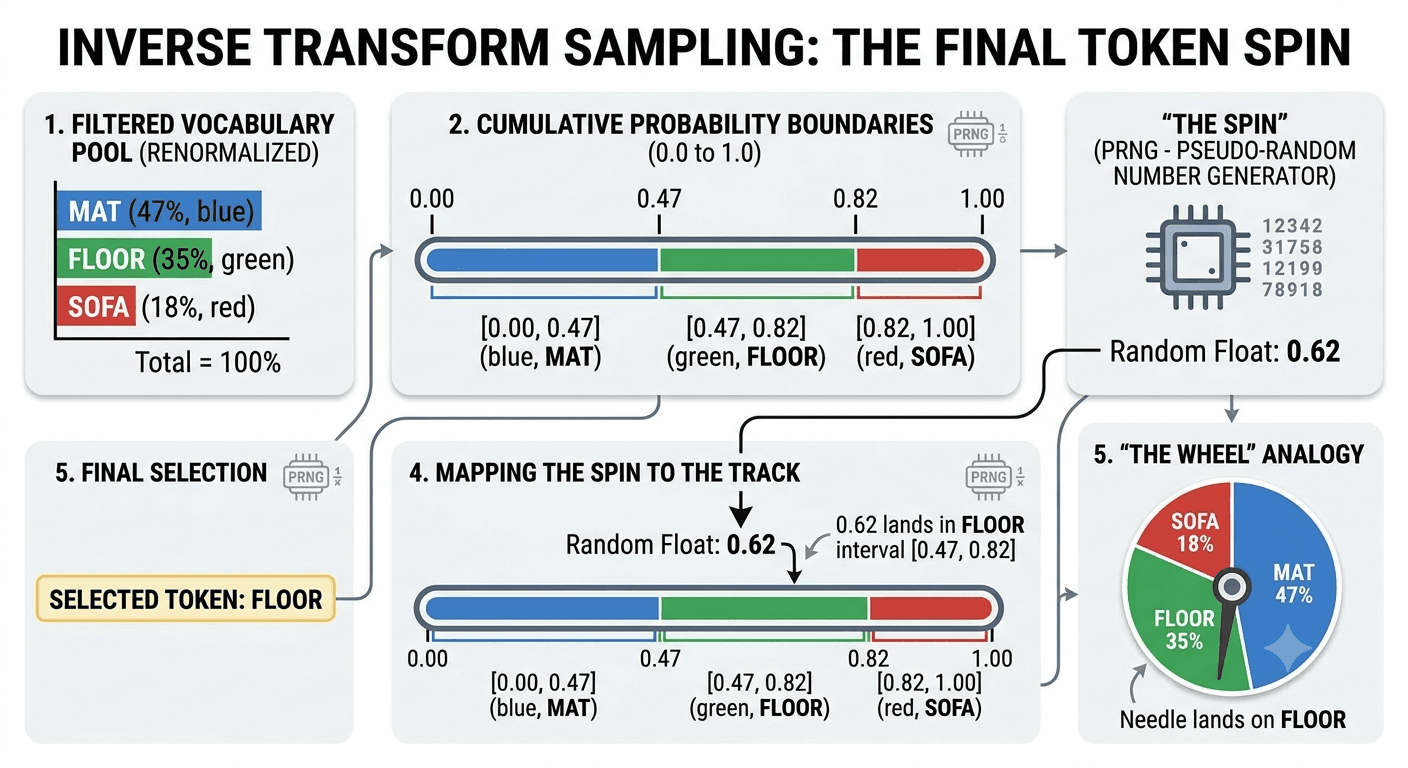
After filtering, the model runs its final choice via Inverse Transform Sampling.
If Top-P yields a final pool of {mat: 0.47, floor: 0.35, sofa: 0.18} (renormalized to equal 1.0), the computer maps them sequentially onto a linear track:

The system draws a number from a Pseudo-Random Number Generator (PRNG). If the float is 0.62, it lands in the "floor" boundary, and that is the token emitted.
Beginners often look at this and wonder if the random number generator introduces flaws or unfair bias. It doesn't. The PRNG is statistically uniform; every decimal between 0.0 and 1.0 has an identical chance of being drawn.
The asymmetry is entirely in the Model's Learned Bias. The model wants "mat" to have a massive 47% chunk of the track because its weights were trained on human text patterns where cats sit on mats. The randomness isn't an error; it's a mechanism to explore the model's pre-existing, learned distribution without getting stuck in a greedy feedback loop.
Alternative and Non-Standard Pipelines
It is a common misconception that every LLM uses all three parameters in a strict sequence (Logits -> Temp -> Top-K -> Top-P -> Sample). In production, workflows vary heavily based on the architecture and the objective:
Top-P Only / Min-P Only: Many modern setups completely skip Top-K to avoid its rigid cutoff constraints.
Constrained Decoding: Libraries like Outlines or Guidance bypass typical sampling entirely. They use regex or JSON schemas to force token probabilities to 0 if they don't match a specific syntax token, overriding traditional Top-P/Top-K filters to guarantee structured data output.
Beam Search: Used primarily in translation or summarization tasks rather than casual chat. It doesn't sample one random token at a time; it maintains a running track of the top N most probable sequences over several tokens, selecting the path with the highest overall cumulative probability.
Advanced Generation Architectures
When you move beyond basic single-token sampling settings, systems scale up to more complex validation mechanisms to balance speed and accuracy.
Rejection Sampling (Best-of-N)
A brute-force approach where the model generates N complete independent responses at a higher temperature. A separate reward model or scoring heuristic evaluates all N completions, selects the one that scores highest against specific criteria, and discards the rest.
Speculative Decoding
An efficiency optimization designed to bypass memory bottlenecks. A tiny, lightweight "draft" model speculatively generates a sequence of 5–10 tokens very cheaply. The massive, main target model then evaluates the entire sequence in a single parallel GPU pass.
If the target model's internal probability distribution aligns with the draft model's choices, it accepts the tokens. If a token falls outside the accepted probability threshold, the main model rejects it, samples a correct token using its own distribution, and the draft model restarts from that point. This delivers the exact mathematical output of the large model at a fraction of the inference cost.
Production Realities
When moving from local experimentation to deploying enterprise applications, keep three platform behaviors in mind:
API Infrastructure Inconsistencies: Model providers do not share uniform implementations. For example, OpenAI's API natively supports presence and frequency penalties but omits a configurable Top-K parameter entirely. Conversely, open-source engines like
vLLMorllama.cppprovide access to the full suite, including Min-P.The Illusion of Temperature=0 Determinism: Setting your temperature to absolute zero invokes greedy decoding, which should yield identical text across runs. However, in large-scale multi-GPU production systems, it does not guarantee 100% determinism. Non-deterministic behavior emerges from the parallelized nature of batch floating-point additions (A + B + C isnot equal to C + B + A down to the lowest decimal point) across high-performance clusters.
Seed controls: To mitigate this drift and enforce stability for evaluation frameworks, use the system's
seedconfiguration parameter to clamp the underlying PRNG to a fixed starting point.
Cheat seat

Conclusion: Balancing the Parameters
Mastering LLM text generation is ultimately an exercise in managing uncertainty. Raw model outputs are inherently chaotic, but by layering parameters deliberately, you gain precise control over the output's structural integrity and creative range:
Temperature shapes the entire probability landscape, dictating whether the model consolidates its confidence or spreads its bets across unexpected options.
Top-P and Min-P act as dynamic safety nets, stepping in after temperature scaling to truncate the vocabulary pool logically based on how confident the model is at any given token step.
Penalties provide real-time runtime adjustments, shifting the probability landscape on the fly to prevent behavioral quirks like stagnation and infinite repetition loops.
When configuring systems for production, the most reliable path is simplicity. Start with cold, greedy decoding (T=0) for deterministic, structural workflows where variance equals a bug. For tasks requiring natural variety or reasoning flexibility, elevate the temperature slightly and use Top-P or Min-P—but tune them independently rather than forcing both to compete. By treating these settings not as isolated dials, but as a unified filtration pipeline, you can reliably tune an LLM's behavioral footprint to match the exact constraints of your application.